
Big Data ist einer der großen Trends unserer Zeit. Mit digitalen Technologien ist die Menge der verfügbaren Daten exponentiell gestiegen. Das wirft die Frage auf, wie diese Daten sinnvoll miteinander verknüpft und genutzt werden können. Und darin schlummert noch ein riesiges ungenutztes Potenzial. Erst sehr wenige Unternehmen nutzen Big Data als Grundlage neuer Geschäftsmodelle. Organisationen, die ihre Geschäftsmodelle weiterentwickeln und digitalisieren, können mit sinnvoller Nutzung von Daten echten Mehrwert für Ihre Kund:innen schaffen.
Um Daten für Innovationen zu nutzen, brauchen Organisationen zunächst einen Überblick, welche Daten sie bereits zur Verfügung haben und welche sie darüber hinaus nutzen könnten. Diejenigen, die Tag für Tag mit den Daten arbeiten, sind jedoch meist nicht in die Geschäftsmodellentwicklung einbezogen und vielen Führungskräften fehlt der Einblick in dieses sehr technische Thema. Dafür braucht es also eine gemeinsame Sprache, die einen interdisziplinären Austausch zu Daten als Innovationsquelle ermöglicht.
Canvas, wie die Business Model Canvas für Geschäftsmodelle oder die Empathy Map für Erkenntnisse aus der Nutzerforschung, haben sich in den letzten Jahren als Tools etabliert. Mit Leitfragen führen sie durch Gedanken und Diskussionen zu den jeweiligen Themen und visualisieren das Ergebnis kompakt auf einer Seite. So erlauben sie es, Gründer:innen und Innovationsteams mit einem schnellen Blick immer wieder den Fokus zu behalten und neu Gelerntes zu ergänzen.
Dieser Blog-Beitrag stellt 3 Werkzeuge vor, mit denen Sie im ersten Schritt einen Überblick über verwertbare Daten in Ihrer Organisation gewinnen können:
Datenstrategie Design-Kit
Martin Szugat hat mit seinem Unternehmen Datentreiber gleich ein komplettes Datenstrategie Design-Kit entwickelt. Am Anfang des 2017 erstmals vorgestellten Prozesses steht die Datenlandschaft Canvas mit einem Überblick und einer ersten Bewertung der vorhandenen Daten.
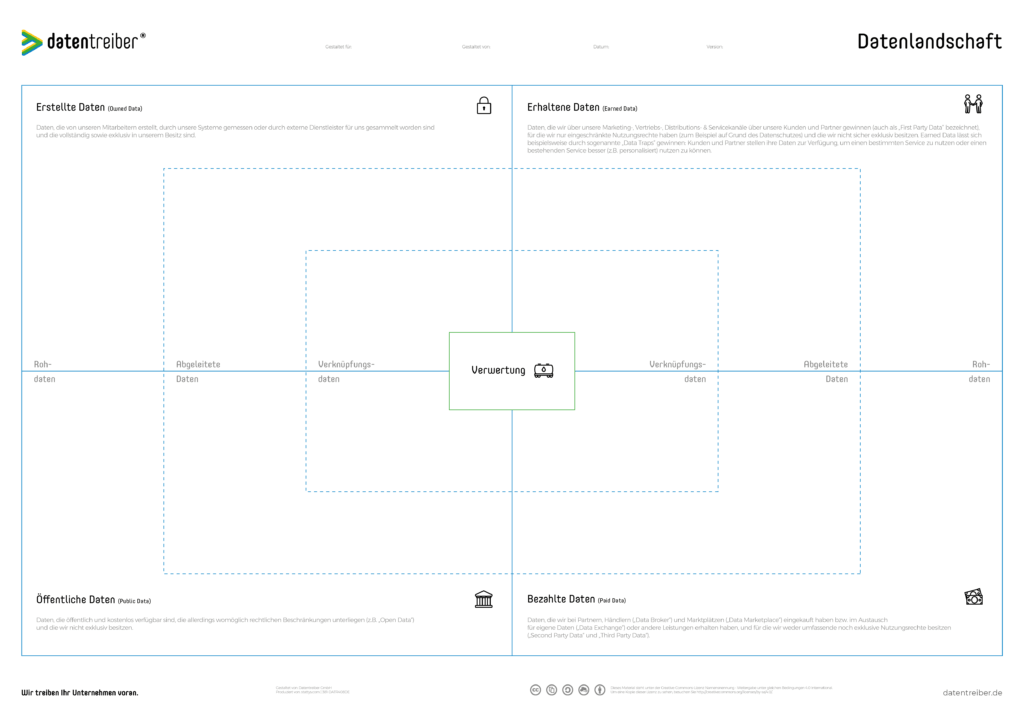
In vier Quadranten werden Datenquellen nach ihrem Ursprung gesammelt: Selbst erstellte Daten, von Kunden und Partnern gewonnen Daten, zukaufbare oder eintauschbare Daten und öffentlich verfügbare Daten.
Je näher zur Mitte die Datenquellen positioniert werden, desto stärker wurden sie bereits bearbeitet. Außen stehen die Rohdaten, abgeleitete Daten im mittleren Bereich wurden bereits verfeinert und Verknüpfungsdaten im inneren Bereich bringen unterschiedliche Datenquellen in Beziehung.
Die Datenlandschaft Canvas wird in der kostenfreien Werkszeug-Sammlung ergänzt um mehr oder weniger bekannte Methoden, wie beispielsweise Stakeholder-Analysen und Wertschöpfungsketten. Ziel ist es, mittelfristig konkrete Anwendungsfälle abzuleiten und umzusetzen und langfristig den analytischen Reifegrad der Organisation zu stärken.
Data Canvas
Weil sie kaum geeignete Tools und Prozesse für datengetriebene Innovation gefunden hat, hat SDSW Gesellschafterin Katrin Mathis 2015 selbst eines entwickelt. Im Rahmen Ihrer Thesis für ihren MBA in Service Innovation & Design entwickelte sie co-kreativ gemeinsam mit der Münchener Analytics-Beratung FELD M und Doktoranten der Technischen Universität München (TUM) die Data Canvas als ergänzendes Tool zu der bekannten Business Model Canvas, die Geschäftsmodelle in neun Feldern auf einer Seite beschreibt.
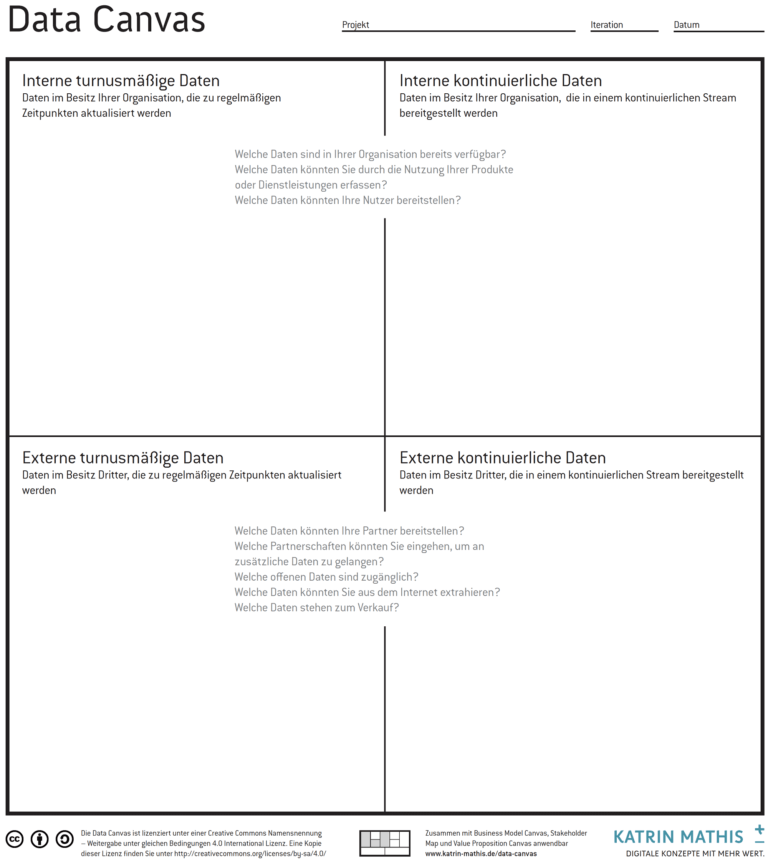
Die Data Canvas ist in vier Felder unterteilt: Die beiden oberen Felder widmen sich internen Daten im Besitz der Organisation und die beiden unteren Felder externen Daten, die beispielsweise Partner bereitstellen könnten oder die hinzugekauft werden könnten. Weiterhin unterscheidet die Canvas zwischen Daten, die schubweise (z.B. monatlich oder jährlich) aktualisiert werden auf der linken Seite und kontinuierlich aktualisierten Daten, die ein weitaus höheres Potenzial für wiederkehrende Einnahmen bieten.
Das Tool ist eingebettet in ein Vorgehen, das sie Data-Need Fit nennt. Darin bilden Data Canvas und eine Akteure-Karte („Stakeholder Map“) die Grundlage für zielgerichtete Nutzerforschung. Organisationen können so Datenquellen identifizieren, die relevante Aufgaben von Kunden unterstützen, Probleme lösen oder Nutzen schaffen könnten. Auf dieser Basis können sie attraktive Wertversprechen, Service-Konzepte und Geschäftsmodelle entwickeln.
Data Loop
Bereits 2014 hat die britische Service Design Agentur Redfront ihre Vorlage eines Data Loop entwickelt. Wie in einem Service Blueprint trennt eine Interaktionslinie die Kundensicht in der oberen Hälfte von der Innen-Perspektive der Organisation unten.
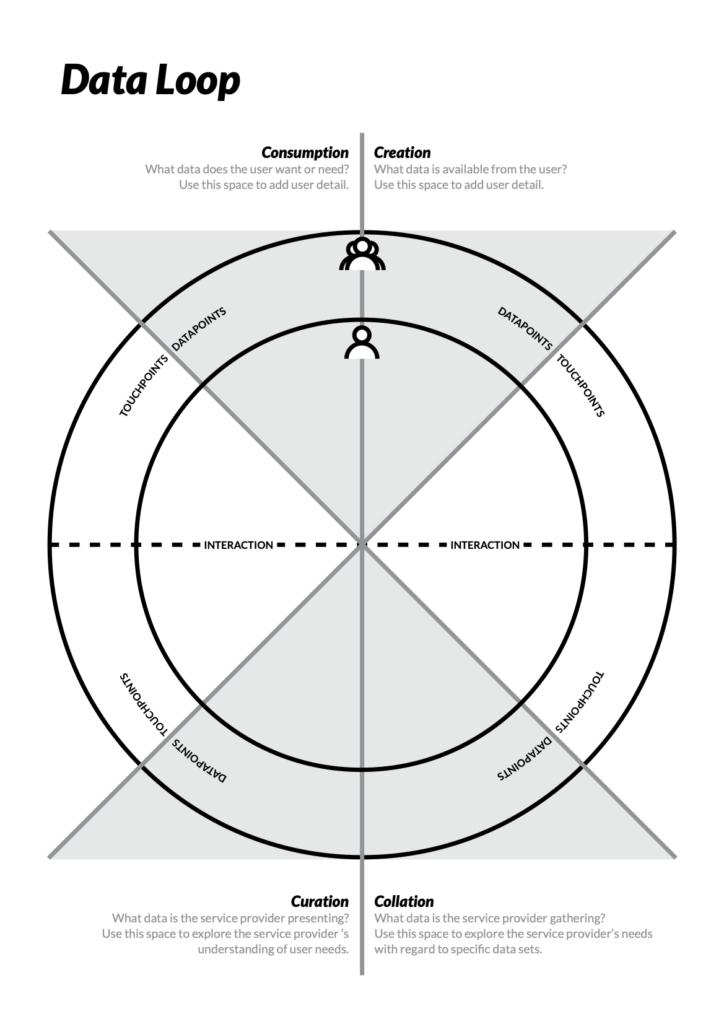
Aus Sicht der Nutzer:innen wird betrachtet, welche Daten sie gerne nutzen wollen bzw. die Nutzererfahrung (UX) verbessern könnten und welche Daten von ihnen zur Verfügung stehen und generiert werden. Aus Sicht der Organisationen wird dargestellt, welche Daten genutzt werden und welche Daten die Organisation sammelt.
Neben Touchpoints, welche alle Berührungspunkte zwischen einer Organisation und den Nutzern beschreiben, führt Redfront den Begriff der Datapoints ein. Datapoints sind die Ereignisse im Laufe eines Service, bei denen Daten eine Rolle spielen.
Im äußeren Ring stehen Daten, die über mehrere Personen hinweg aggregiert genutzt werden, während sich der innere Ring Daten einer einzelnen Person widmet. Außerhalb der Kreise findet sich Platz für zusätzliche Informationen, wie beispielsweise potenzielle Partnerschaften, Barrieren und Sicherheitsbedenken.
Der Data Loop kann sowohl mit bestehenden Erkenntnissen genutzt werden, um die Sicht zwischen Nutzern und Daten abzugleichen, als auch datengetrieben von der unteren Hälfte, um potenzielle Nutzer für vorhandene Daten zu entdecken.
Welches Werkzeug eignet sich wann?
Das sind nur drei Beispiele für Vorlagen, die Ihnen helfen, zu Ihren Daten ins Gespräch zu kommen. Als visuelle Werkzeuge strukturieren sie die Diskussion und bleiben als bildliche Dokumentation in Erinnerung. Idealerweise werden sie als lebendige Dokumente genutzt, die immer wieder angeschaut, ergänzt und verwertet werden.
Die genannten Tools bauen methodisch auf Service Design, Design Thinking und Lean Startup auf und lassen sich in nutzerzentrierten Innovationsprozessen anwenden.
Neben der Exploration der Datenquellen ist Nutzerforschung essenziell, um die Bedarfe von potenziellen Nutzer:innen zu kennen, um im nächsten Schritt daran anknüpfen zu können. Der Data Loop geht bereits auf ein Verständnis der Nutzerbedürfnisse ein. Wie diese strukturiert ermittelt werden können, zeigt das Tool nicht auf und erfordert damit mehr Erfahrung in den begleitenden Prozessen. In den anderen beiden vorgestellten Tools liegt der Fokus zunächst auf den reinen Daten und erst in ergänzenden Werkzeugen auf den Nutzer:innen und ihren Bedürfnissen. Mit dem Datentreiber Design-Kit und dem von Katrin Mathis beschriebenen Data-Need Fit zeigen sie mögliche Vorgehen auf, um Daten für Innovationen zu relevanten Nutzerbedürfnissen zu nutzen.
Datenlandschaft Canvas und Data Canvas sind ähnlich aufgeteilt mit internen Daten oben und externen Daten unten. Im Unterschied zur Data Canvas unterscheidet der Datenlandschaft Canvas nicht nach Frequenz der Daten, sondern schaut noch stärker auf deren Herkunft.
Damit eignet sich der Datentreiber Canvas eher für Organisationen mit höherem analytischen Reifegrad, die langfristig Analytics Kompetenz ausbauen und nutzen wollen. Data Canvas und Data Loop hingegen sind nutzerzentrierter aufgebaut und näher an den Prozessen für Service-Innovation und neue Geschäftsmodelle. Sie eignen sich auch für einzelne Innovations-Projekte in Organisationen, die sich bisher weniger mit Daten auseinandergesetzt haben.
Wenn Sie Unterstützung bei der datengetriebenen Innovation in Ihrer Organisation benötigen, beraten wir Sie gerne dazu, einen für Ihre Organisation passenden Prozess aufzusetzen und begleiten diesen methodisch und moderierend mit unserem frischen Blick von außen.
Titelbild: © kasami